Standardize ML problem solving using SKlearn Pipeline — Part -2
This is the continuation of article — part -1, In the previous article we discussed, what is Pipeline and how to define it. In a short,- Pipeline is a useful tool for encapsulating multiple different transforms with an estimator, in a object as shown below -

Most of the examples demonstrating Sklearn Pipeline uses pre-define Sci-kit learn methods, but actual cases aren’t that straight. Here in this article we will see how can we customize the Pipeline class and use the user defined data processing functions. To achieve this goal lets check these two use cases -
- Use case 1
In this use case, we’ll see how to apply different data transformation to different features of the same dataset. Then we’ll see how to try different estimator and select the best performing and at last use GridsearchCV, for hyperparameter tuning. Lets begin ..
a. Create a Dataset suitable to our use case:
I’ve used IMDB Dataset and created numerical features based on the text feature, such as : Length, No of Stopwords, No of commas etc. Also I’ve dropped few entries so that we can use data imputing in our pipeline. Code is available at git repo


b. Data Pre-processing:
Now, how can we use custom pre-process function to our pipeline ? Before we dig that lets see the syntax used to define the Pipeline. Pipeline is defined by passing the list of the tuples to Pipeline module. Here tuple contains name of the transform method and Data Transform/Estimator Method i.e (‘Method Name’, Data Transform/Estimator Method). as shown below.

The only condition is : The Data Transform/Estimator Method has to be a Sci-kit learn method api. So to use custom predefined Data-preprocessing function as a Pipeline method, we need to wrap it up into sci-kit learn “ Base Estimator of Transformer” As shown in below code snippet
Link for the complete code : git repo
#Import sklearn base estimator to wrap the function
from sklearn.base import BaseEstimator# This is your non-sklearn data transform function specific to your # dataclass Process():
def __init__(self):
pass
def transform(self,x):
#k=np.array([int(i)+10 for i in x]).reshape(-1, 1)
#print(k.shape)
return np.array([int(i)+10 for i in x]).reshape(-1, 1)
# This is how we use 'BaseEstimator' to wrap "Process" using #"Transform" class
class Transform(BaseEstimator):
def __init__(self):
self.t = Process()
def fit(self, x, y=None):
return self
def transform(self, x):
return self.t.transform(x)
As shown in above code snippet, class Process is my user defined function and I build class Transform (Name can be any) to wrap my user-defined function using sci-kit learn’s “BaseEstiamator” class.
As discussed earlier, lets apply different data transforms to each of these features: 1. review — Apply Lemmatization followed by Tfidf vectorization. 2. comma: Data imputation with mean value and then use custom preprocessing function. 3. Stopwords : Data imputation with max frequent entry then use custom pre-processing. 4. No transformation for length feature as shown below
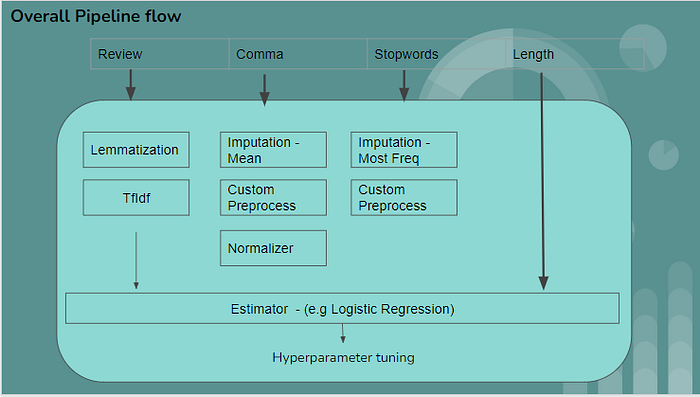
Again the question remains the same, how are we going to apply different pre-processing techniques to each feature and use it in a single pipeline. The answer is : we create separate pipeline module for each of the feature and then combine it into single pipeline. As Pipeline is a sci-kit learn estimator we can use ColumnTransformer to combine these modules and pass the feature column data to respective pipeline module, as shown in below code snippet
# 1. comma featurescomma_pipe=Pipeline([
('imputer1',SimpleImputer(missing_values=np.nan, strategy='mean')),
('process1',Transform()),
('Normalize1',Normalizer()),
])# 2. stopwords featurestop_pipe=Pipeline([
('imputer1',SimpleImputer(missing_values=np.nan, strategy='most_frequent')),
('process1',Transform()),
])# 3. reviewreview_pipe=Pipeline([
('lemma',Lemmatize()),
('tfidf', TfidfVectorizer(max_features=2500)),
])# combine all the pipeline modeules to create Data transform pipelinefrom sklearn.compose import ColumnTransformerpreprocessor = ColumnTransformer([
("comma", comma_pipe, ["comma"]),
("stopwords", stop_pipe, ["stopwords"]),
("review", review_pipe, "review"),
],remainder="passthrough")pre_pipe=Pipeline([
('preprocess',preprocessor)
])
This is how we can create a single pipeline combining different data pre-processing method. Lets see how we can try different model and use the GridsearchCV, for hyperparameter tuning.
c. Training and Hyper-parameter tuning
In last article, I’ve shown how we can use different pipeline for various models and select the best performing one. Adding to that there is one more advantage of using Pipeline i.e. we can fine tune the performance based on model parameters as well as Data pre-processing parameters. Here I’ve used GridsearchCV, and finetuned the pipeline based on Data pre-processing parameter such as TfIdf max features, as shown below.
# Hyperparameter tuning using GridsearchCV# 1. Logistic Regressionlogistic=Pipeline([('preprocess',pre_pipe),
('lg',LogisticRegression()),
])scoring='roc_auc'
cv=3
n_jobs=-1param_grid = [{
'preprocess__preprocess__review__tfidf__max_features': [2500, 5000, 10000],
'lg__C': [1., 3.],
}]grid = GridSearchCV(logistic, cv=cv, n_jobs=n_jobs, param_grid=param_grid,
scoring=scoring, verbose=1)
grid.fit(df.drop('sentiment',axis=1), df['sentiment'])
grid.cv_results_
The line : ‘preprocess__preprocess__review__tfidf__max_features’ is used to back propagate and tune the parameter. Character “__” is used as “looking inside”. So the above code is saying that, it is looking inside preprocess pipeline and then looking inside pipeline module named “review” to tune parameter “max_features”. The above combination would train the model 18 times giving the result as:
'preprocess__preprocess__review__tfidf__max_features': 10000}],
'split0_test_score': array([0.93870469, 0.94175626, 0.95158427, 0.93878446, 0.94194691,
0.9435572 ]),
'split1_test_score': array([0.9338236 , 0.93723736, 0.93919153, 0.93327454, 0.93810763,
0.95264361]),
'split2_test_score': array([0.93801378, 0.94105734, 0.94186284, 0.93820217, 0.94144045,
0.9363261 ]),
'mean_test_score': array([0.93684736, 0.94001699, 0.94421288, 0.93675372, 0.94049833,
0.94417563]),
'std_test_score': array([0.00215664, 0.0019861 , 0.00532522, 0.00247161, 0.00170308,
0.00667593]),
'rank_test_score': array([5, 4, 1, 6, 3, 2])}2. Use case 2
Similar to Customized Data pre-processing, in this use case we’ll see if we can use user defined model/estimator (Non Sci-kit learn model). Here I’ve defined a model that will check if the given example is more that the mean of training distribution.
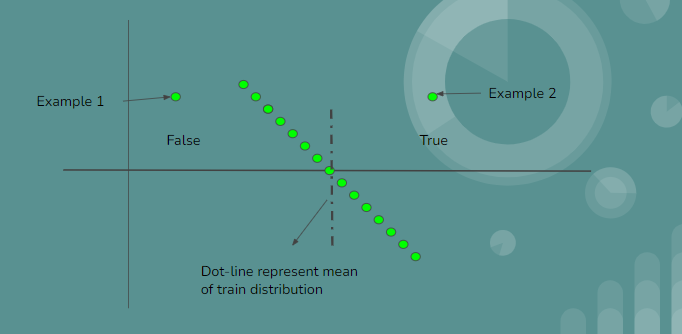
As shown in above fig: Centre inclined line is training distribution. Black dot-line represents the mean of distribution. Model will label example 2 as True as it is greater than the mean and example 1 is labeled as False as it is less than mean. Similar to Data custom data pre process method, we need to wrap this into sci-kit learn base estimator as shown in below code snippet
Link for the complete code : git repo
from sklearn.base import BaseEstimator
from sklearn.base import RegressorMixinclass Custom_Model(BaseEstimator, RegressorMixin):def __init__(self):
"""
"""
super().__init__()
self.mean=Nonedef fit(self, X, Y=None):
"""
Fit global model on X features to minimize
a given function on Y.@param X
@param Y
"""
self.mean=np.mean(X)
return selfdef predict(self, X):
"""
@param X: features vector the model will be evaluated on
"""
ans=[i>=self.mean for i in X]
return ans
Hope you got an idea about how to customize sci-kit learn’s pipeline.
Referring few articles to read :